We tried LlamaParse, but you deserve ChatDOC PDF Parser better.
LlamaParse has received a lot of recommendations recently. However, after testing several documents, we're disappointed to find that compared to ChatDOC PDF Parser, LlamaParse still has a lot of room for improvement.
Such as missing content recognition, difficulty in identifying complex tables, and the inability to recognize headers and footers...Please open the thread for more details.
ChatDOC consistently demonstrates outstanding accuracy and reliability across various document types, including financial reports, academic papers, and legal documents. The key lies in our years of accumulated expertise in Panoramic Document Structure Extraction
If you'd like to experience ChatDOC PDF Parser, we welcome you to join our waitlist at pdfparser.io.
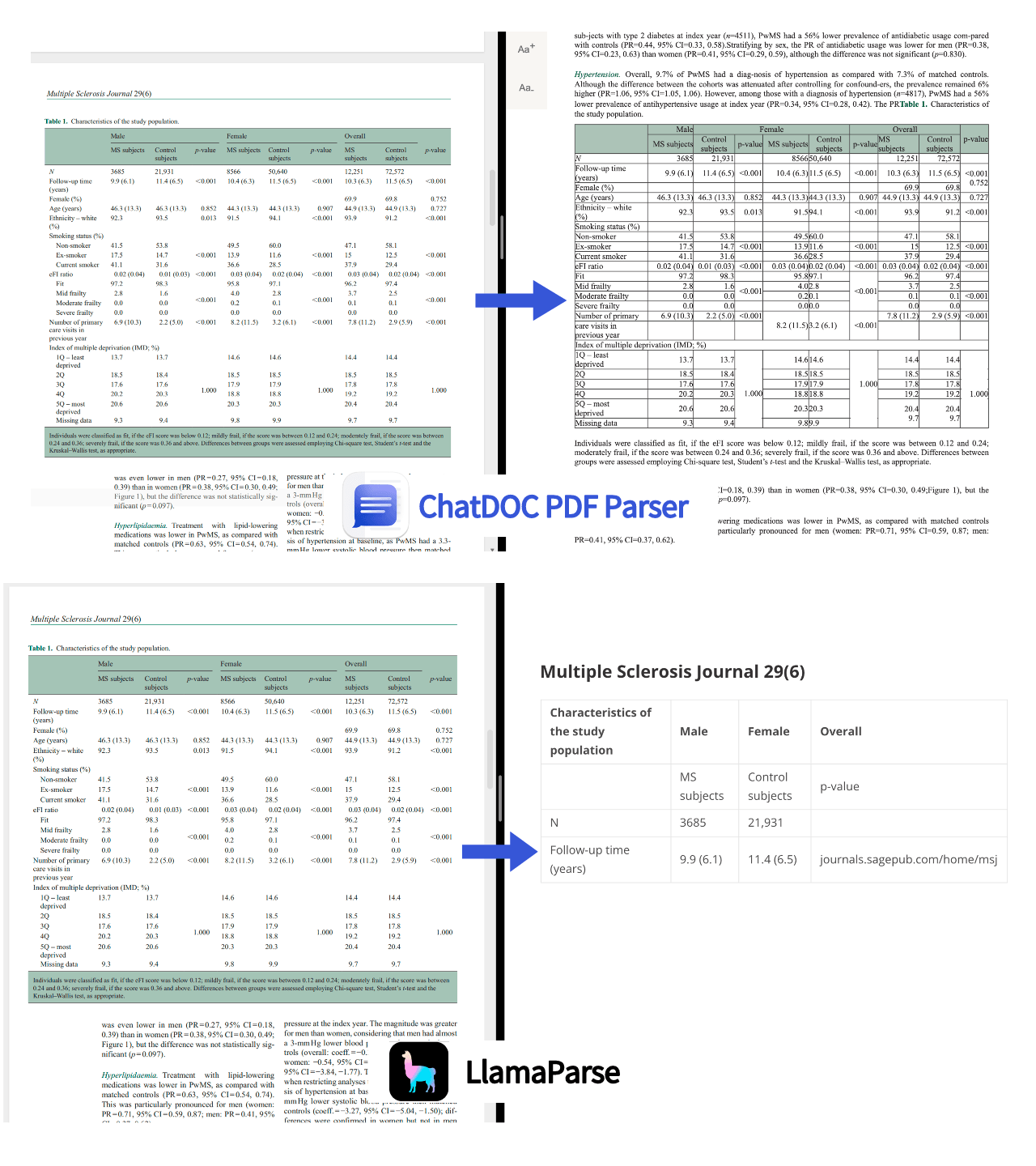
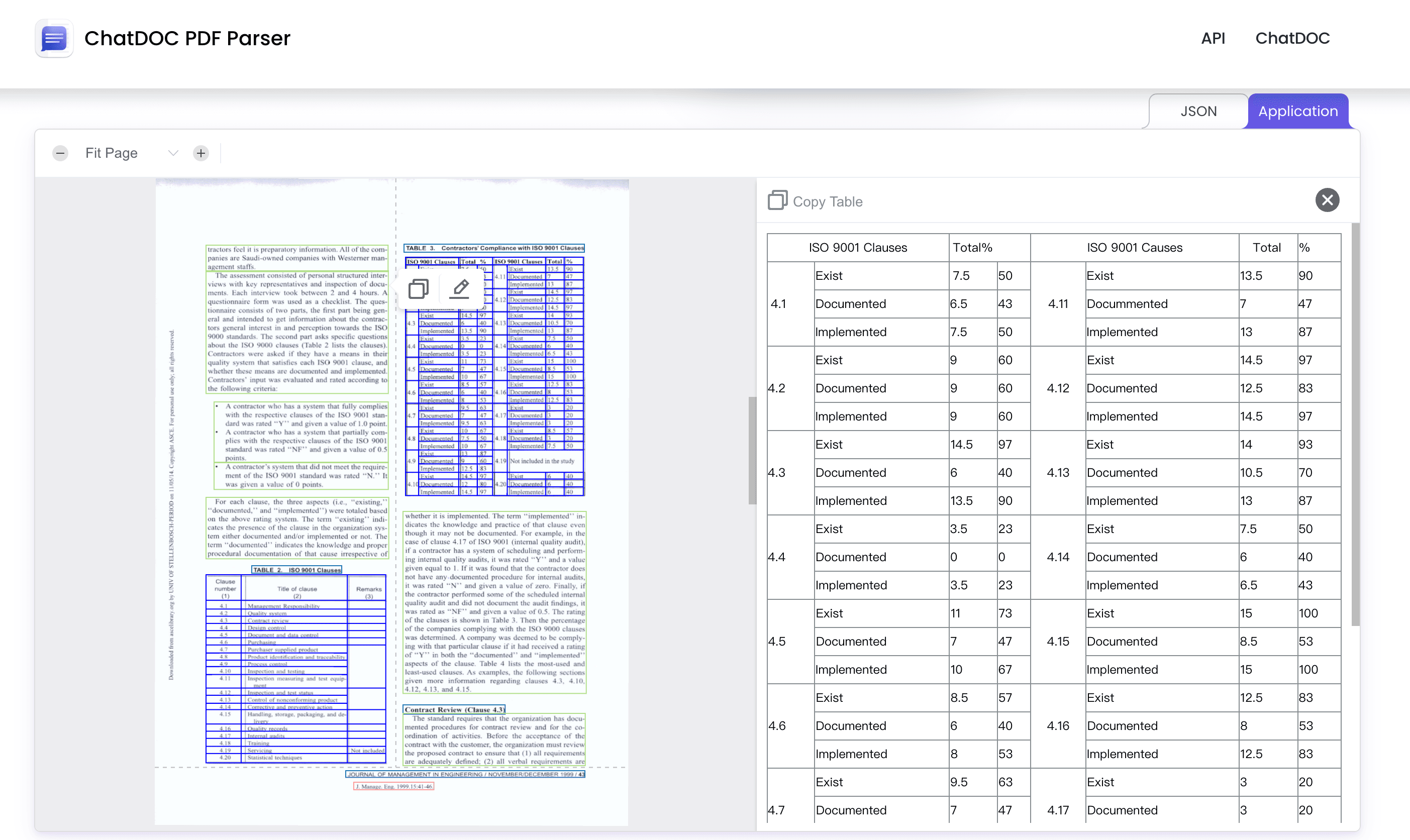
1. A lot of content is missing.
Many pieces of content are noticeably absent. This deficiency extends beyond merely intricate table data to encompass paragraph content as well. What's more, although embedded tables can be parsed, the extracted data is often found to be inaccurate. As we all know, the accuracy and reliability of table information are crucial, especially in scenarios like financial reports
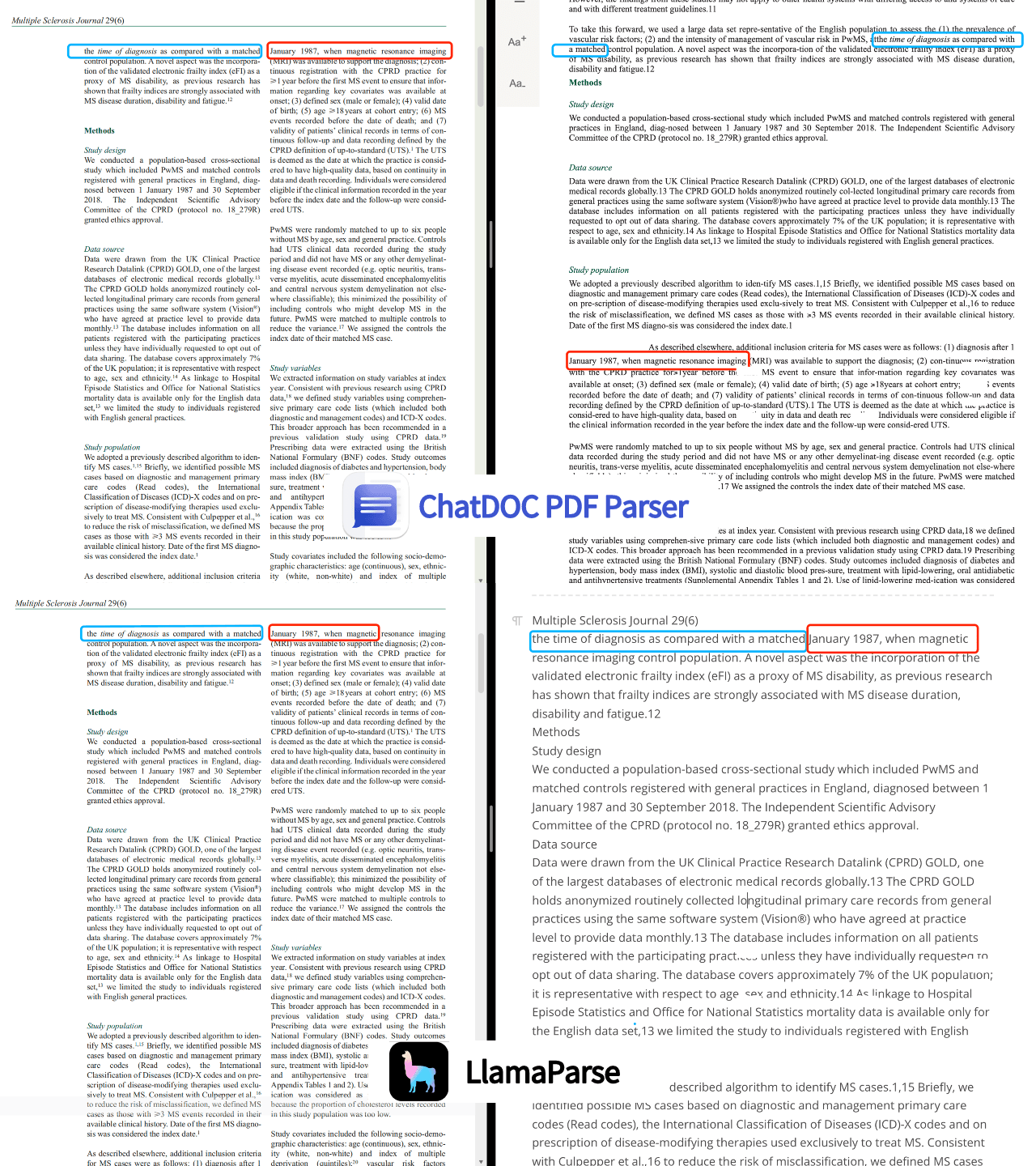
2. Recognition of multi-column PDFs is poor.
We tested several multi-column PDFs, and while some could be recognized, others could not. Since the majority of papers are in multi-column PDF format, this is a pressing issue that needs to be addressed urgently.
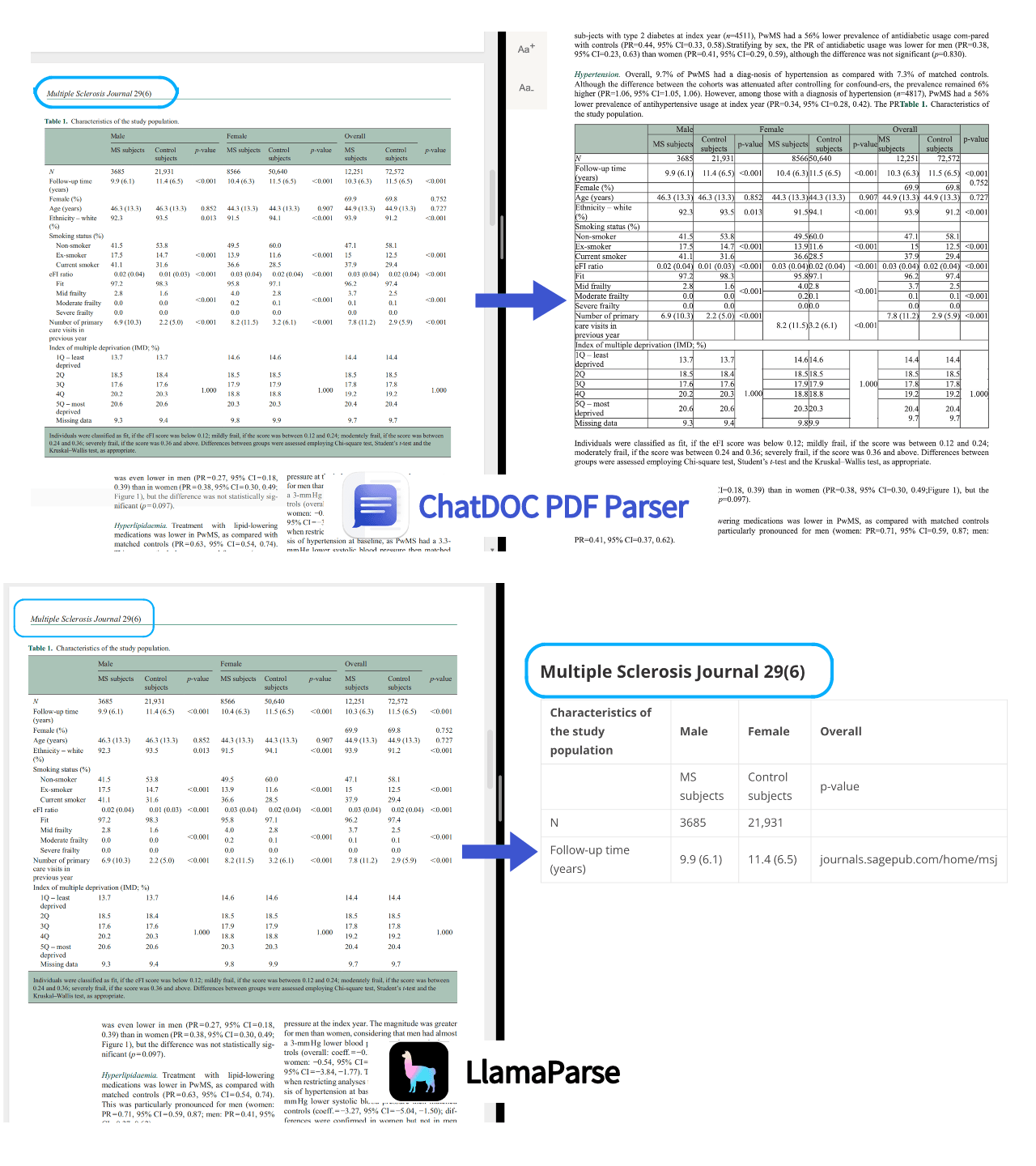
3. Charts are being parsed as tables.
Currently, LlamaParse does not have the ability to recognize charts, so it directly parses charts into tables. In contrast, ChatDOC PDF Parser is able to restore the original content and structure, including the correct presentation of charts.

4. Unable to recognize header and footer.
This detail may seem minor, but it significantly influences the final performance.
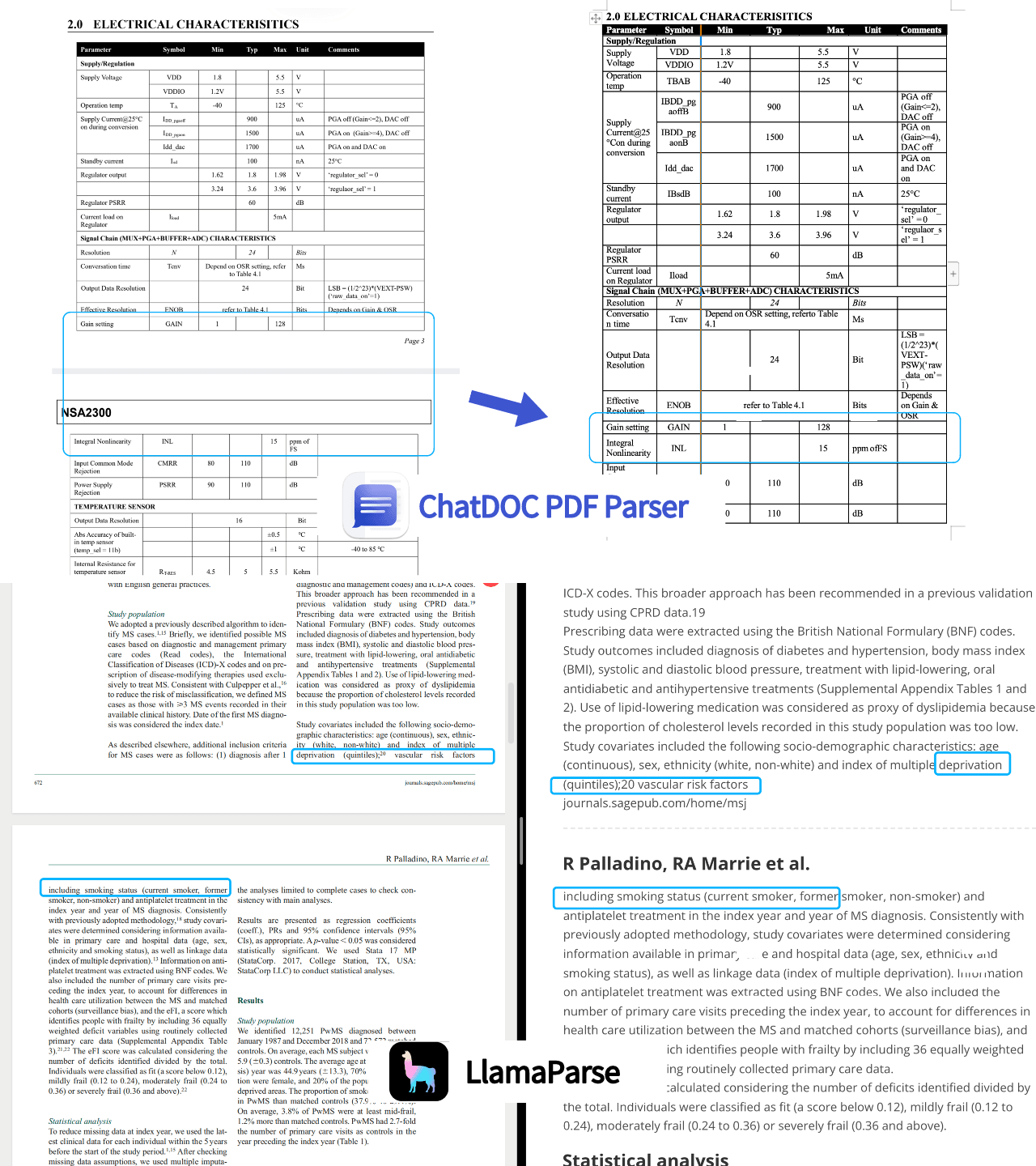
5. Paragraph content is being recognized as tables.
In the reference section, LlamaParse mistakenly recognizes the article content as tables, while ChatDOC PDF Parser continues to perform reliably.

6. Multi-page contexts are not being merged.
We speculate that it is because the header and footer are not recognized, so LlamaParse cannot determine. In contrast, ChatDOC PDF Parser can even recognize cross page tables and merge them.
What is ChatDOC PDF Parser?
Unlock data from any complex PDFs with unparalleled precision. Our advanced AI models extract tables, paragraphs and images from PDFs, turning unstructured data into actionable insights.
If you'd like to experience ChatDOC PDF Parser, we welcome you to join our waitlist at pdfparser.io.


Related Articles
Best 5 Academic AI Tools for Researchers to Save Time in 2024
In 2024, academia enters an efficiency era with AI tools transforming research and writing. Explore the top 5 AI tools saving time and reshaping scholarship.

Why is GPT 4 struggling to read PDFs? You need an ultimate "Chat With PDF" APP
Numerous forum discussions highlight frequent GPT-4 errors in PDF reading. Let's delve into the technical perspective to explore the underlying reasons behind these errors, and why you might be in need of the ultimate "Chat With PDF" APP.

Best 5 AI Tools for Podcast Makers and Lovers
In recent years, podcasts have surged in popularity as a medium for disseminating information across diverse fields. Today, we will introduce five AI tools for podcast makes and lovers.
