OpenAI introduces GPTs, But ChatDOC Still Excels in PDF Chat
The OpenAI press conference was a blockbuster event in the AI world, with ChatGPT receiving a major update.
For users, the most significant update is GPTs — now, everyone can customize their own GPT assistant. This feature became available to all GPT-4 users on November 10th.
Users can enhance their personalized GPT by uploading documents to supplement its specialized knowledge, and configure it with abilities like web browsing, DALLE image generation, code interpretation, and retrieving specific information through plugins or websites.
At the API level, GPT-4 Turbo introduced six enhancements: an expanded context window, improved model control, updated knowledge, multimodal capabilities, open GPT-4 fine-tuning, and increased call rate limits.
Among these, the context window has been increased to 128k tokens, equivalent to inputting 300 pages of a book at once.
Every time GPT releases new features, a question arises: is there still a market for AI products with similar functions?
This time, it's generally believed that AI Q&A products, especially those based on documents, will be impacted. Previously, GPT couldn't interact directly with PDFs, and PDF AI Chat products like ChatDOC(https://chatdoc.com) addressed a major pain point.
Now that GPT can also handle PDFs, do they still have business space? The answer is yes.
Next, this article will discuss where the opportunities for document Q&A AI lie under OpenAI's relentless pursuit:
- Understanding complex pages and tables
- Better embedding and knowledge recall
- Deepening into business scenarios to solve professional problems
1. ChatGPT: Excellent with text, but not as proficient with documents
The new version of ChatGPT can now handle files, but not as adeptly as it handles text content. A Twitter user commented that although GPT4 can now process files, the user experience is still not as good as ChatDOC.
The most common scenarios for interacting with documents are answering user questions based on product manuals and providing auxiliary analysis based on professional documents like financial reports.
We selected two public documents, the "Tesla User Manual" and "The New Development Bank's Financial Statements", to conduct a usability test with ChatGPT, GPTs, and ChatDOC.
1.1 Tesla User Manual
First, we posed a detailed question:
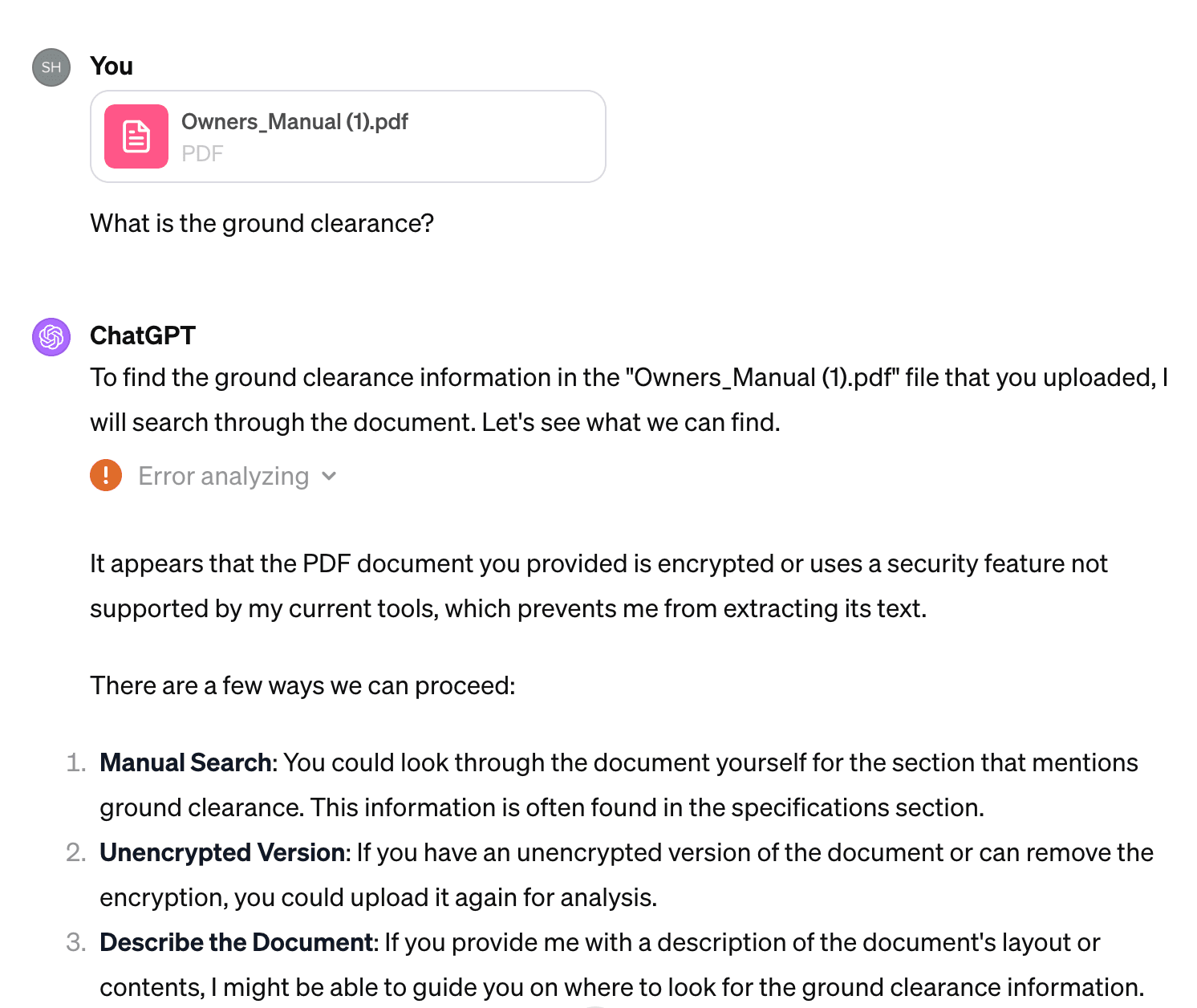
What is the ground clearance?
ChatGPT told us: "It appears that the PDF document you provided is encrypted or uses a security feature not supported by my current tools, which prevents me from extracting its text."
Using the new GPTs feature, we customized a Tesla Expert Bot, uploading both the Chinese and English manuals to its knowledge base.
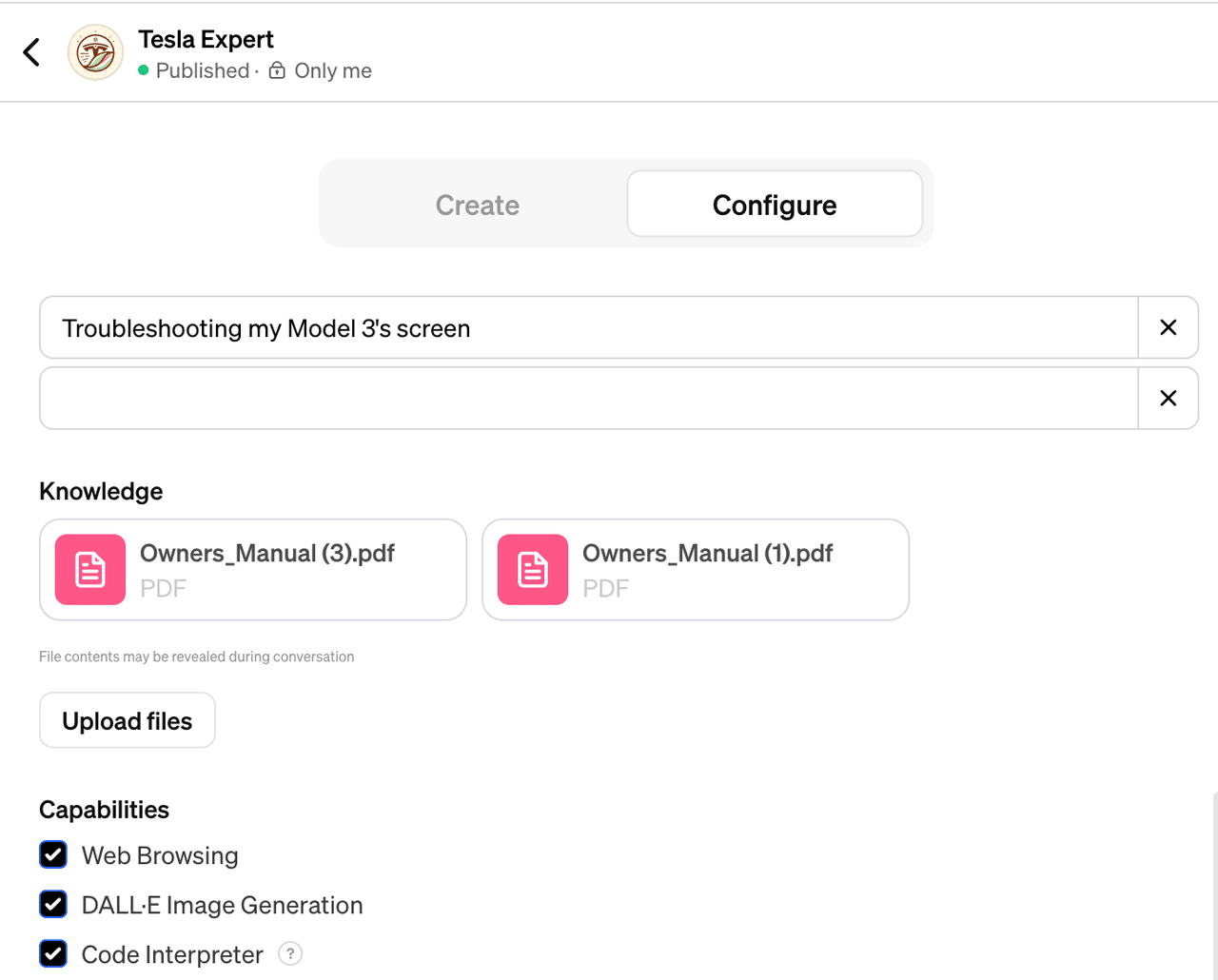
Tesla Expert Bot successfully answered this question. But it's the same old issue with GPT: it confidently provides an answer, but how can I know if the answer is correct? (Fortunately, it provides the correct answer this time)

Here comes ChatDOC. When we uploaded the same file, it not only provided the correct answer, 5.4 inches, but also cited the table in the original text.
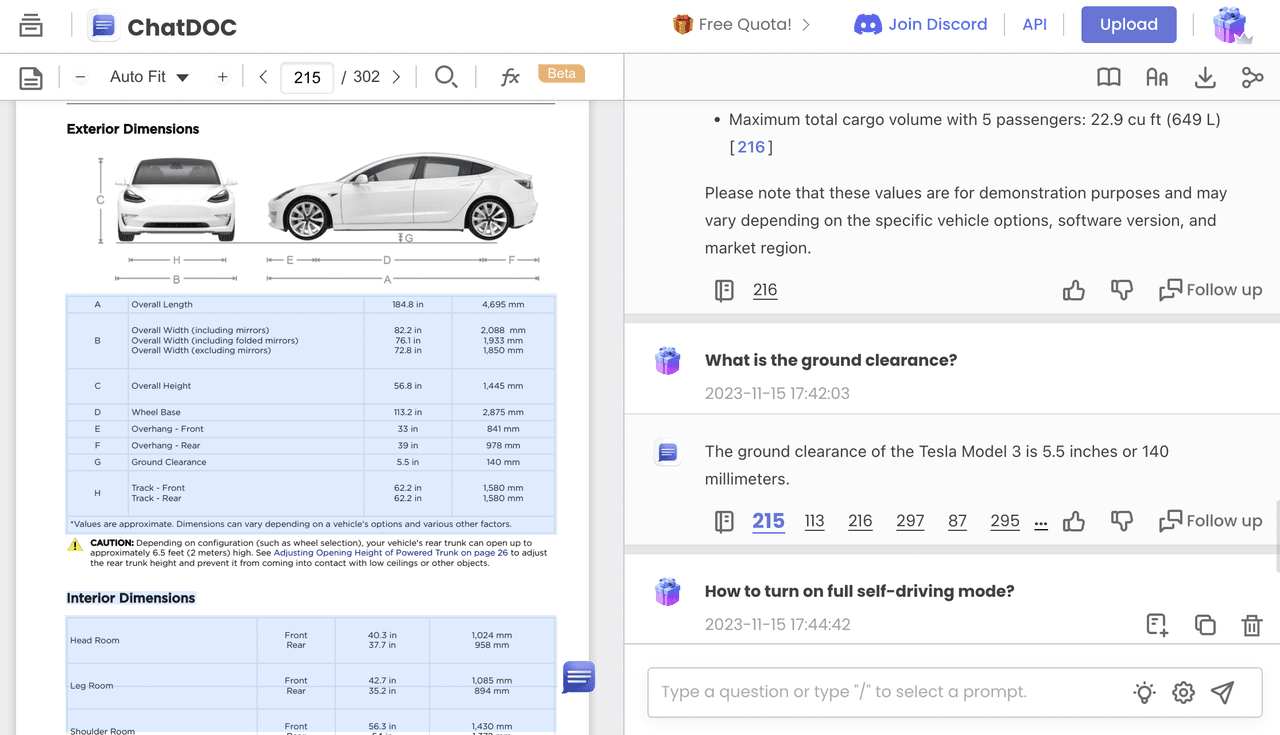
Let's try another question:
How much cargo can I carry at most in terms of size?
ChatGPT again failed to read the file.

Our custom GPTs Tesla Expert successfully answered this question, without giving any sources. This time, however, we weren't as fortunate in obtaining accurate information: The front trunk volume was incorrectly identified as the total cargo capacity.
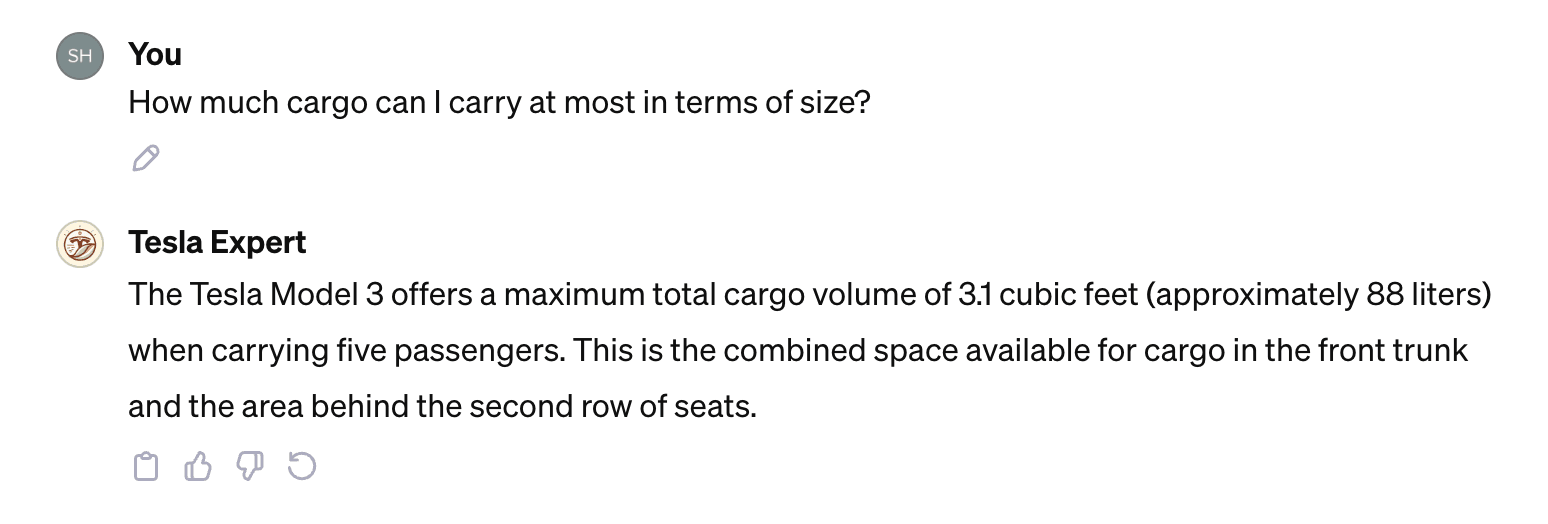
ChatDOC, again, provided a perfect response: the correct answer, including the source, and answered in detail.

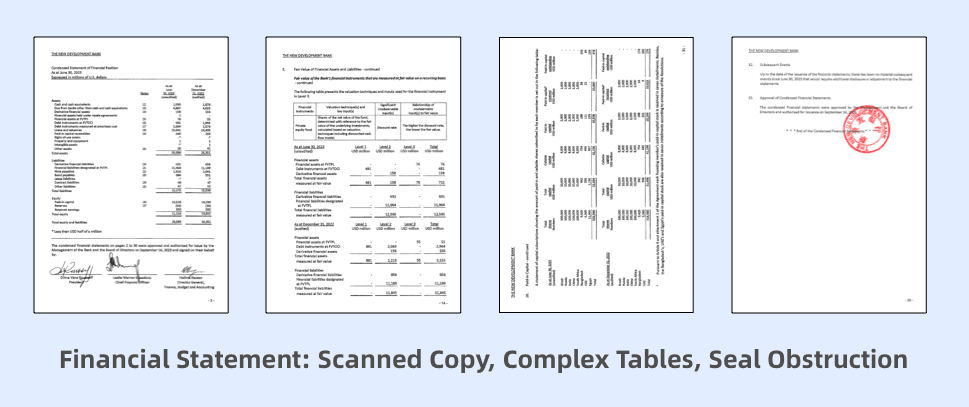
1.2 Financial Statement
Let's try with a financial report, which is a scanned document. After uploading the report, we asked:
Did the company make more money this year compared to last year?
ChatGPT, despite being responsive, failed to provide an answer.
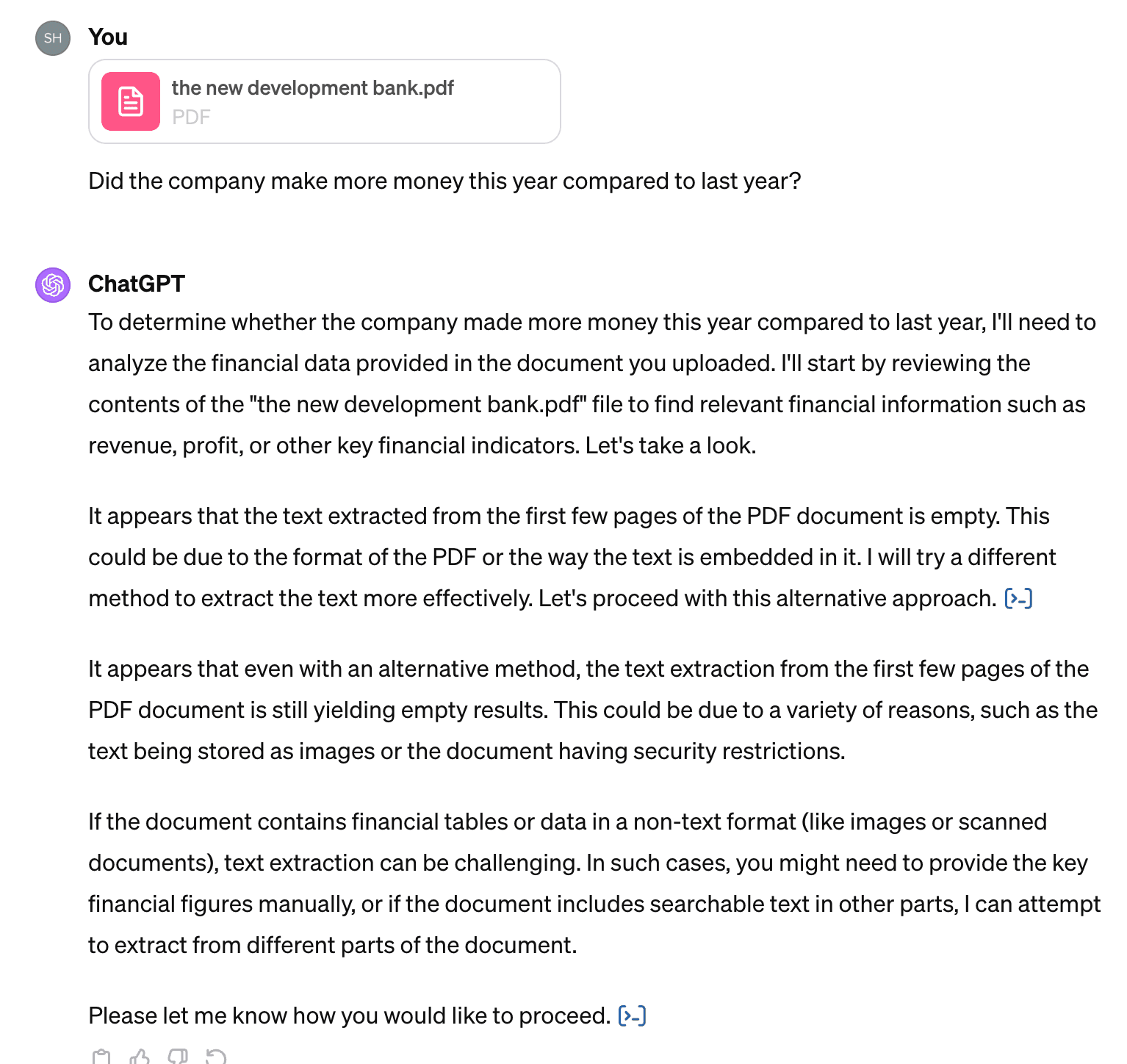
The Financial Expert Bot built with GPTs says, the scanned file limits its ability to directly extract data.

ChatDOC, on the other hand, performed consistently well, providing the correct answer and the original text source.

2. Why Can't GPT Answer Questions When the Information Is Right in the Document?
Looking into the "Error analyzing" details, we found that GPT used the PyPDF2 PDF parser, which is also the first recommended parser by Langchain.

However, our tests on PyPDF2 revealed that it can only extract text without paragraph or table information.
For example, when we input the following page into PyPDF2:
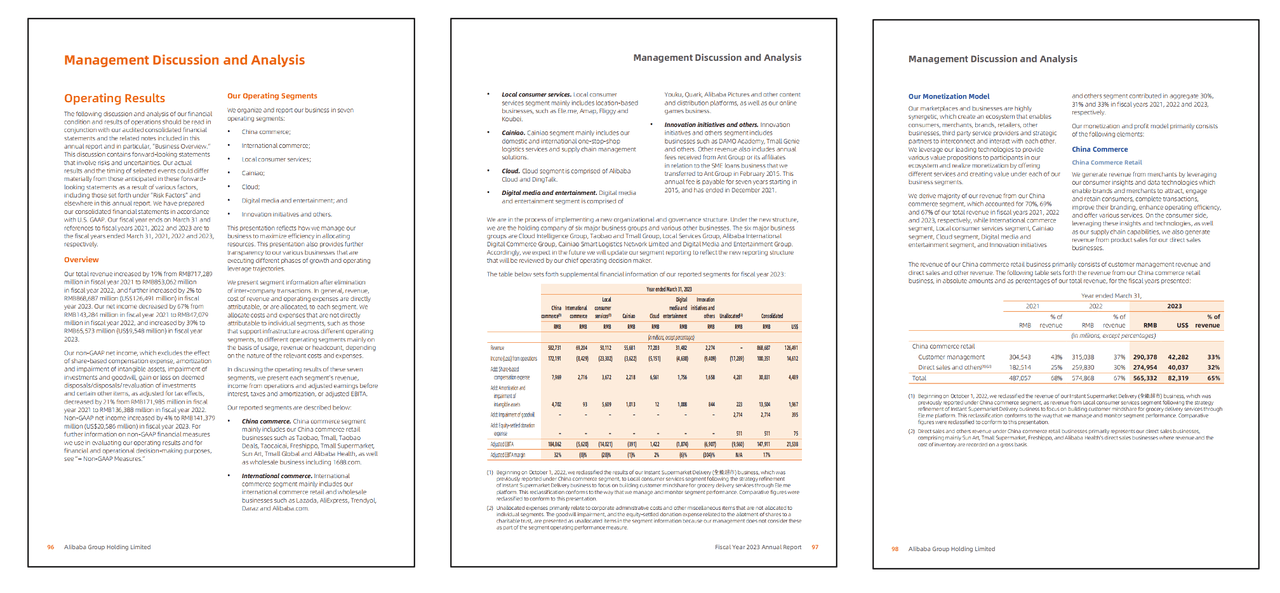
PyPDF2's output looked like this:

It merely extracted the text, losing the document's original column layout and the relationships within tables, resulting in jumbled information.
If the information we're asking about is hidden in a table or a small part of a longer document, ChatGPT can't access it.
The Tesla owner's manual is exactly the kind of document with multi-column layouts and many tables.

Clearly, the PDF parser developed by ChatDOC performs better, not only understanding complex layouts but also accurately interpreting tables. It can extract table information with ease.
Additionally, ChatGPT currently doesn't support scanned documents. In the financial industry, about 15% of reports and financial statements are scanned documents. ChatDOC's high-precision OCR greatly reduces interference from stamps and blurry scans, ensuring accurate information extraction.
In comparison to ChatDOC, a specialist in "document Q&A," ChatGPT has a broad range of functions but lacks specialization:
- It can't process scanned documents.
- It struggles with complex document layouts.
- It doesn't understand tables.
- It can't display the original text source, making fact-check difficult.
Data is the new oil, and ChatDOC can mine more high-value data from documents.
3. Longer Context Window ≠ Higher Accuracy
As we've discussed in previous articles, a pragmatic approach to adding specific domain knowledge to large models is retrieval-augmented LLM: first, split long documents into chunks, calculate vectors, store them, and then recall the most relevant document segments based on user queries, adding them into the prompt before feeding them to the large model for answers.
The need for "retrieval augmentation" arises because large models have a length limit for each round of Q&A. For example, GPT-3.5 previously couldn't exceed 4096 tokens in total for input and output, roughly equivalent to 3000+ words.
After the GPT-4 API update, the context window has been increased to 128k tokens, equivalent to inputting 300 pages of a book at once.
Does this mean large models can now directly understand lengthy documents without retrieval augmentation and provide high-quality answers?
Probably not yet. Users have reported that when PDFs exceed a thousand pages, GPT's answers are 80% likely to be incorrect.
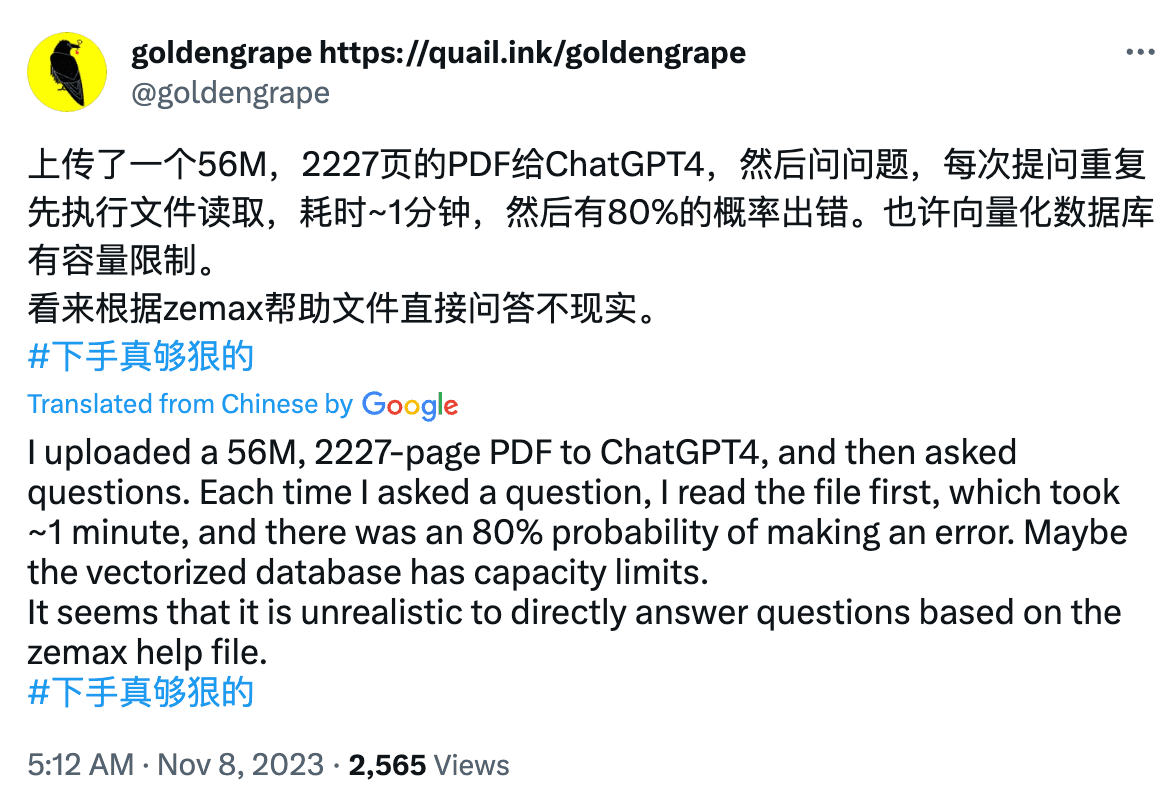
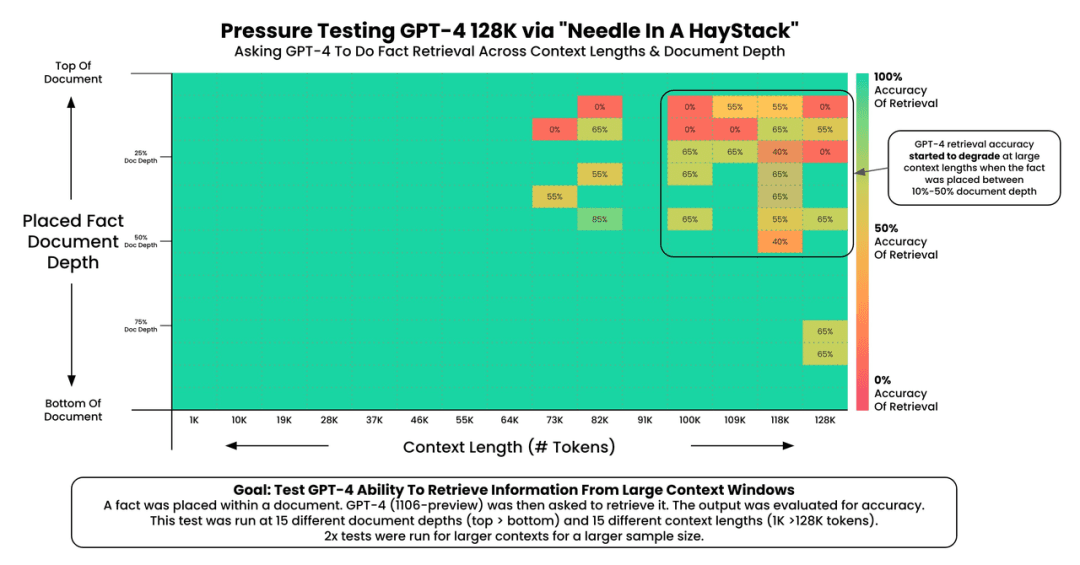
User @Greg Kamradt conducted more in-depth testing, which he called the "needle in a haystack" test.
He used Paul Graham's essays to create test texts of varying lengths, randomly inserting the sentence, "The best thing about San Francisco is eating a sandwich in Dolores Park on a sunny day," and asked GPT, "What's the best thing about San Francisco?"
He found that:
- GPT-4's recall performance starts to drop when the text exceeds 73K tokens.
- Recall performance is poorer when the fact to be recalled is located between 7%-50% of the document.
- If the fact is at the beginning of the document, it's recalled regardless of the context length.
As shown, the longer the text, the worse GPT's performance in finding information. Therefore, RAG remains necessary.
ChatDOC uses retrieval augmentation, continuously optimizing recall, and can support Q&A for documents up to 3000 pages. Moreover, ChatDOC's embedding model uses higher-dimensional vectors, storing more detailed information.
Especially when the correct answer is scattered across tables, ChatDOC's recall results are better.
Optimizing embedding is another competitive edge for ChatDOC.
4. Identifying Application Scenarios and Landing in Industries
Finally, without specific scenarios, AI's capabilities, no matter how strong, remain toys rather than tools.
The next opportunity for AI lies in the application layer. Beyond the capabilities of basic models, the ability to genuinely solve users' problems is what every AI application should consider.
Document Q&A, when combined with scenarios, can create deeper barriers to entry.
The company behind ChatDOC,PAI Tech, has long served the financial industry's informationization. Based on years of industry knowledge, ChatDOC has been specially optimized for investment banking legal regulations, company information disclosure supervision, and equity incentives, among other specific scenario knowledge bases. Besides the version for C-end users, a professional B-end version is also in the process of collaboration and implementation.
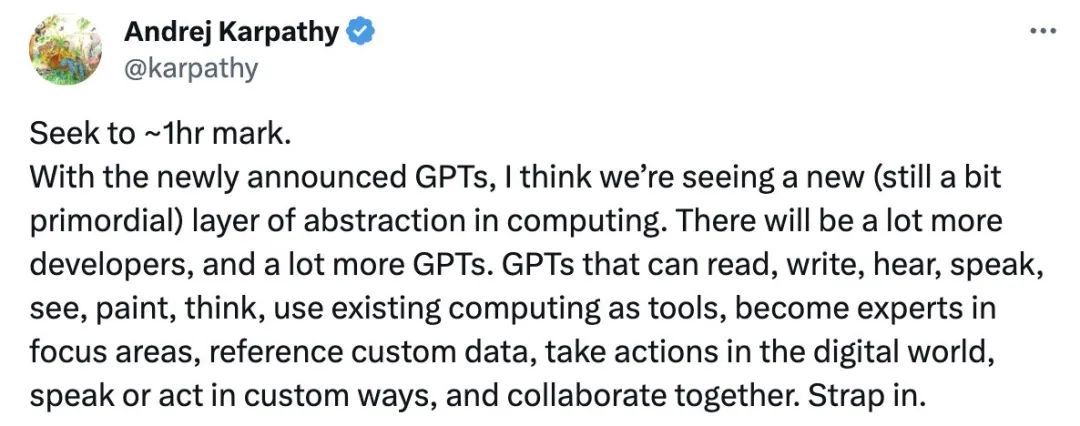
OpenAI co-founder Andrej Karpathy once said that when building AI Agents, ordinary people, entrepreneurs, and geeks are in a level playing field with OpenAI, and may even have an advantage.
He noted that every time the OpenAI team reads a new AI Agents paper, they find it very cool: "Because we didn't spend five years on it, and we don't know much more than you."
Therefore, pinpointing scenarios, uncovering demands, and focusing efforts on data and engineering are ChatDOC's third competitive strength.
With this update, it's evident that in addition to technology, OpenAI is increasingly focusing on product experience and ecosystem building.
Andrej Karpathy mentioned that in the future, there will be more developers and more GPTs. GPT can read, write, listen, speak, see, draw, think, and become an expert in key areas, referencing custom data and acting or speaking in a customized way.
ChatDOC will also be a force among many AI intelligent applications, helping large models to better understand documents, mine data, recall knowledge, and apply it in various industries.


Related Articles
Revolutionizing Retrieval-Augmented Generation with Enhanced PDF Structure Recognition
This article examines methods for extracting structured knowledge from documents to augment LLMs with domain expertise. It focuses on the document parsing stage, which is crucial for retrieving relevant content in RAG systems.

ChatDOC - The Best PDF AI Chat App
ChatDOC is an advanced ChatPDF app optimized for intensive study and work with documents. It leverages cutting-edge AI to provide accurate responses, in-context citations, and comprehend tables better than alternatives. Just upload, ask, get concise summaries, and instantly locate information without having to skim or scroll through pages.

A Long-Context Re-Ranker for Contextual Retrieval to Improve the Accuracy of RAG Systems
RAG systems often miss key context due to document chunking. ChatDOC’s Long-Context Re-Ranker enhances contextual retrieval through structural parsing and semantic reorganization, boosting Q&A accuracy by 13.9%. This improves AI’s ability to process corporate knowledge bases and personal documents more precisely.