ChatDOC Guide: How to make good queries?
You must have heard ChatDOC — AI copilot for document reading. Simply upload your files(.pdf, .doc, scanned files), ask AI anything, and get instant answers with cited sources.
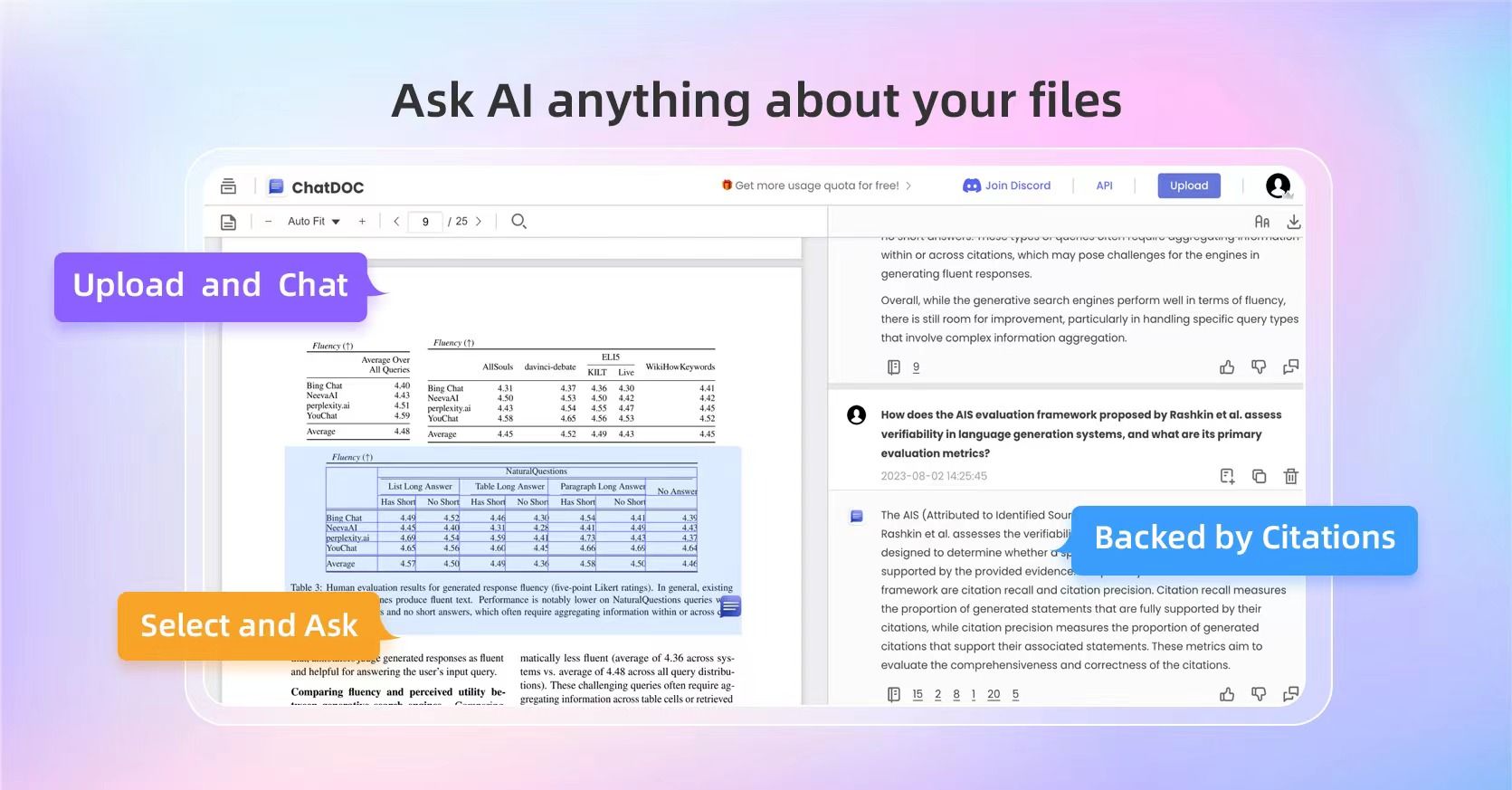
It is a great assistant for speed reading documents, but it is not omnipotent. Due to the nature of LLM, different ways of phrasing a question might lead to entirely different answers. This underscores a vital realization: the art of crafting the right question isn’t just good to have, it’s essential.
So, how do you tap into the reservoir of knowledge and pull out precisely the information you seek?
Remember this mantra for asking questions:
Ask in small batches, use threads. Stay on-topic and objective. Be specific, don’t sweat the details.

1. Focus: Ask one question at a time in main chatbox

🤔 Why:
The more focused the question is, the more relevant the document snippets ChatDOC uses will be, and the better the answering effect will be. If too many questions are asked at one time, the amount of information ChatDOC provides for each question will decrease. This is because ChatDOC works by matching questions with the most relevant document snippets. Also, due to the token limitations of large language models, the amount of document snippets that can be used in one Q&A turn is limited.
2. Thread: Ask follow-up questions in Threads

🤔 Why:
In the main chatbox, ChatDOC’s product design does not automatically retain context between exchanges. Each question is separate and needs to be complete. After entering Thread, ChatDOC retains all context under the current topic. At this point you can choose to have it answer strictly according to the original text, or freestyle under this topic.
3. On-topic: Avoid letting ChatDOC “go freely” in the main chatbox, stay focused on documents

🤔 Why:
In the main chatbox, our product design stipulates that ChatDOC can only answer based on the document itself in the first Q&A turn.
We want to ensure the reliability of the answers as much as possible. If we let it freestyle in the first Q&A turn, it means the generated answers cannot be traced back to sources. Chatting with ChatDOC would then be no different from chatting with ChatGPT directly: the AI won’t know where the information comes from and is very likely completely unrelated to the document.
In Thread, we allow ChatDOC to freestyle, using information beyond the documents to answer. At this point ChatDOC can retain the context from the previous Q&A turn, and riff off of that while still relating back to the document itself.
4. Objective: Ask objective questions, avoid subjective opinions.

🤔 Why:
ChatDOC does not make its own preferences or value judgements, it can only answer based on the information provided in the documents. Therefore, please avoid subjective questions of personal preference when asking questions, and directly ask about the objective information expressed in the documents about a certain object/matter.
5. Specific: Provide criteria for judgement, avoid broad questions
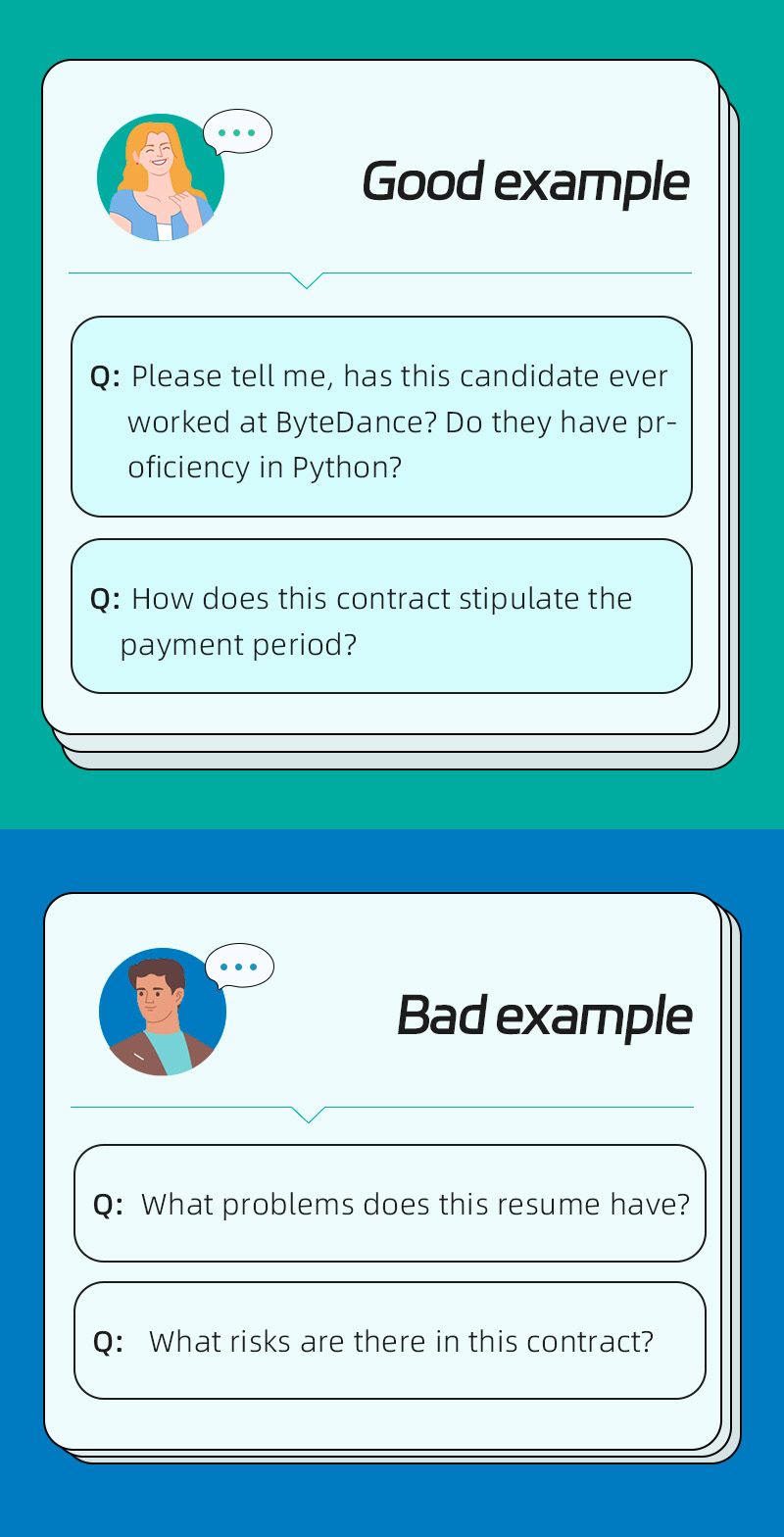
🤔 Why:
Overly broad questions make it difficult for ChatDOC to: 1. Retrieve and locate relevant snippets, 2. Stay within input and output token limitations.
Firstly, it cannot replace our own thinking to define “which candidate is suitable” or “which contract has risks.” It can only retrieve relevant content based on the criteria we provide: e.g. Peking University graduate, worked at a certain company; e.g. payment period less than 7 days. We can also add our own criteria to Custom Prompts for convenient future use.
Secondly, ChatDOC cannot translate or proofread entire documents. Large language models have input and output token limits per turn, e.g. GPT-3.5 currently has a 4096 token limit, roughly equivalent to 3000+ words. That means the combined input question, retrieved document snippets, and output answer cannot exceed 3000 words per turn. But we can have it translate or proofread select passages by choosing excerpts. If a translation cuts off mid-answer, we can continue generating in Thread.
6. Don’t sweat the details: Ask about content itself, not page numbers/frequency

🤔 Why:
ChatDOC works by matching questions with relevant document content. Inputting “Chapter 5” or “Page 10” is unlikely to allow the AI to understand what we need. Accordingly, we should point out the specific content of sections and page numbers, and ask concrete questions directly.
We also don’t need to ask “on which page is the information about xxx” — ChatDOC will automatically provide reference pages, we just need to click to trace back.


Related Articles
Revolutionizing Retrieval-Augmented Generation with Enhanced PDF Structure Recognition
This article examines methods for extracting structured knowledge from documents to augment LLMs with domain expertise. It focuses on the document parsing stage, which is crucial for retrieving relevant content in RAG systems.

OpenAI introduces GPTs, But ChatDOC Still Excels in PDF Chat
ChatDOC outperforms GPT's file-chat in 3 ways: understanding complex pages and tables, better embedding and knowledge recall, combining with business scenarios to solve professional problems.

ChatDOC - The Best PDF AI Chat App
ChatDOC is an advanced ChatPDF app optimized for intensive study and work with documents. It leverages cutting-edge AI to provide accurate responses, in-context citations, and comprehend tables better than alternatives. Just upload, ask, get concise summaries, and instantly locate information without having to skim or scroll through pages.
